p-value : erreur fréquente d’interprétation.
Conclure, de l’absence de différence significative d’un test statistique, à l’équivalence des éléments comparés, est une erreur trop fréquente. Elle est à rapprocher du problème de l’inversion de la charge de la preuve.
Lors d’un congrès vétérinaire national, l’un de nous a assisté à la présentation d’un essai par un laboratoire. Celui-ci veut proposer un nouveau protocole de synchronisation de chaleurs des vaches.
Il a monté une expérience où il traite N animaux avec un premier protocole et N animaux appariés avec un second. A partir des résultats de diagnostic de gestation, il fait un test statistique, d’hypothèse, où l’hypothèse nulle est « Il n’y a pas de différence entre les deux protocoles » et l’hypothèse alternative est « Il y a une différence entre les deux protocoles ». Le résultat de l’expérience montre une p-value* supérieure à 5%. D’un point de vue statistique La différence observée entre le premier et le second protocole n’est donc pas une différence significative. Notre laboratoire en conclut donc qu’il n’y a pas de différence entre ces protocoles de synchronisation. Alors que tout ce qui précède est correct, cette dernière étape du raisonnement est fausse !
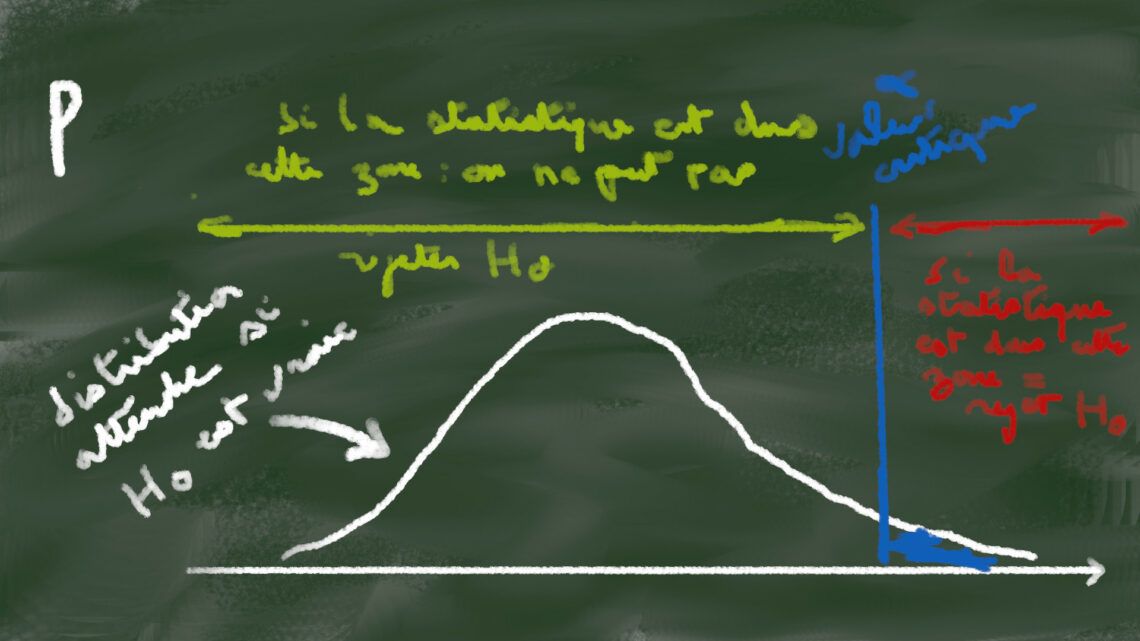
Un test d’hypothèse classique (X2, analyse de variance, Pearson, Student …) fonctionne grosso modo de la façon suivante : dans la population étudiée, je veux vérifier que truc existe (ça c’est l’hypothèse appelée alternative H1). Je postule que truc n’existe pas (c’est mon hypothèse nulle appelée H0). Et oui, on prouve que quelque chose existe en rejetant la possibilité qu’il n’existe pas. Donc partant du postulat qu’on a H0 et en appliquant le test statistique sur les mesures dans notre population étudiée, ce test calcule la probabilité qu’il soit possible d’observer les résultats obtenus dans l’essai si H0 est vraie : le fameux petit p. Si cette probabilité est inférieure à 5% (valeur choisie à priori qui peut être différente) alors on rejette l’hypothèse nulle. On admet alors l’hypothèse alternative H1 : truc existe.
Comment interpréter alors si la p-value est supérieure à 5% ? Ben on n’interprète pas et surtout on ne dit pas qu’H0 est vraie ! Forcément puisqu’on a fait le test en présumant qu’elle était vraie ! C’est une tautologie, un raisonnement circulaire. Le cheval blanc est blanc parce que c’est… un cheval blanc…
Reprenons l’exemple de notre laboratoire, la conclusion ne pouvait être, au mieux, que : « nous avons échoué à montrer une différence entre les deux protocoles ». Peut-être qu’effectivement, il n’y a pas de différence. Cependant il est possible aussi que l’essai manque de puissance et qu’il échoue à montrer une différence qui pourtant existe.
Comment aurait-il pu s’en sortir ? Intervertir les hypothèses, c’est-à-dire partir sur l’hypothèse nulle « il y a une différence » et une hypothèse alternative « il n’y a pas de différence », ça ne marche pas ( c’est même mathématiquement impossible). Il reste donc deux options. Soit multiplier les études et, en échouant à montrer une différence, cela augmente, de fait, la crédence en cette hypothèse. Soit plus simplement en réalisant non pas un test « classique » mais un test de non infériorité ou d’équivalence mais ce genre d’essai clinique coûte plus cher et demande une grande rigueur.
Voilà voilà. Nous vous parlerons peut-être un jour des inférences abusives fréquentes dans les essais cliniques vétérinaires..
* calculée à l’aide d’une analyse de variance